Python - pandas:Excelデータの読み書きをし、統計情報を計算、抽出する
初めに
Python と pandasを使えば、データ操作やデータ分析を効果的に行うことができます。本記事は、pandas に初めて触る人に向けて、基本的な操作を記述します。
Index
準備
以前、python で初めてデータ分析をする人向けに記事を書いております。まずは、そちらをご覧ください。
フォルダで excel ファイルと python ファイルを作成し、VSCode で開きます。


操作
pandas のインポート
次のコードを書いて pandas をインポートします。
import pandas as pd
Excel ファイルに書き出し
pandas の to_excel 関数を使用して Excel ファイルに書き込むことができます。データの読み込み、編集などの練習をするために、データをランダムに作成し、Excel ファイルに書き出しておきます。
import pandas as pd import random # データの生成 random.seed(0) # 乱数のシードを設定して再現性を確保 study_hours = [random.randint(1, 10) for _ in range(40)] test_scores = [random.randint(50, 100) for _ in range(40)] # データフレームの作成 data = {'勉強時間': study_hours, 'テストの点数': test_scores} df = pd.DataFrame(data) # Excelファイルに書き出し df.to_excel('study_data.xlsx', index=False) print("データが作成され、study_data.xlsxに保存されました。")
pandas は excel ファイルを読み書きするために openpyxl というライブラリを使用します。もしModuleNotFoundError: No module named 'openpyxl' とエラーがでたら、TERMINAL から次のコマンドを実行し、インストールしてください。
pip install openpyxl
インストール後、再度実行すると、excel ファイルが同じフォルダに作成されます。

Excel ファイルの読み込み
先ほどのファイルとは別の .py ファイルを作成し、Excel ファイルを読み込みます。
import pandas as pd # Excelファイルの読み込み df = pd.read_excel('study_data.xlsx')
read_excel 関数を使うことで読み込むことができます。
head 関数, tail 関数
# Excelファイルの読み込み df = pd.read_excel('study_data.xlsx') # データの先頭行を表示 print(df.head()) # データの末尾の行を表示 print(df.tail(3))

head 関数と tail 関数を使うと先頭行、末尾の行を表示させることができます。引数を指定しない場合は 5 行表示されます。
describe 関数
# Excelファイルの読み込み df = pd.read_excel('study_data.xlsx') # 基本的な統計情報を表示 print(df.describe())
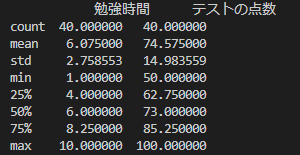
統計情報の計算
# Excelファイルの読み込み df = pd.read_excel('study_data.xlsx') # 勉強時間の平均を計算 mean_study_hours = df['勉強時間'].mean() print(f'平均勉強時間: {mean_study_hours:.2f} 時間') # テストの点数の最大値を計算 max_test_score = df['テストの点数'].max() print(f'最高テストの点数: {max_test_score} 点') # テストの点数の歪度を計算 skewness_test_scores = df['テストの点数'].skew() print(f'テストの歪度: {skewness_test_scores} 点')

pandas では、一般に使われる統計情報を計算する関数が用意されています。
抽出
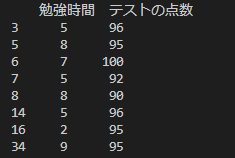
# テストの点数が70点以上のデータを抽出 score_over_70 = df[df['テストの点数'] >= 90] print(score_over_70)
上のように条件からデータを抽出することができます。
# 勉強時間が9時間以上で、テストの点数が30点未満のデータを抽出 study_under_3_hours_score_under_60 = df[(df['勉強時間'] >= 9) & (df['テストの点数'] < 30)] print(study_under_3_hours_score_under_60)
& を使うことで増やすことができます。条件を満たすデータがない場合、次のように表示されます。
