Python -「Python初学者のためのPandas100本ノック」やってみた①
初めに
「Python初学者のためのPandas100本ノック」に挑戦してみる過程をまとめています。本記事は始め方と第1問から第13問までについて、書いています。
Index
始め方
手順
次の手順で始めることができます。




回答例の確認
回答例の確認は、コメント化されている "pring(ans[])" の前にある # を削除し、実行すると確認できます。
#print(ans[1]) #回答表示
Pandas基礎(1 - 13)
1(最初の5行を表示)
指示がコメントで記述してあるので、その指示通り実行されるように入力していきます。

今回は、最初の5行を表示したいので、head 関数を使い、実行します。実行すると次のように結果が表示されます。

2(最後の5行を表示)
df.tail()
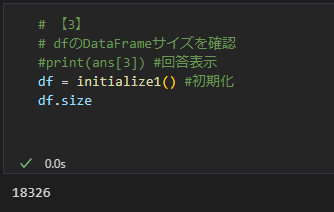
3(DataFrameサイズの確認)
DataFrameの要素数を表示したい場合は、size を使います。
df.size
DataFrame の次元を表すタプルを確認する場合は、shape を使います。
df.shape
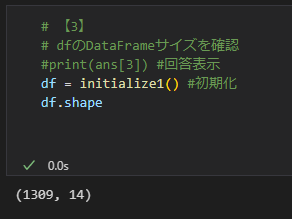
この場合、14 個の要素を持つタプルが1309 個あることを表しています。1309 × 14 = 18326 (size)になります。
4(フォルダ内のcsvファイルを読み込み, 最初の5行を表示)
csvファイルを読み込むには, read_csv() 関数を用います. 引数でフォルダを指定します。
df2 = pd.read_csv("../input/data1.csv")
df2.head()
5(指定した列を昇順に並び替えて表示)
sort_values() 関数を用いて、要素をソートします。デフォルトでは昇順、ascending=False を指定すると、降順になります。

複数要素を指定する場合は、次のように記述します。
df.sort_values(["fare", "age"])
6(DataFrame をコピーする)
copy() 関数を用いて、DataFrame をコピーすることができます。
df_copy = df.copy() df_copy.head()
次の2つは挙動が異なるため、注意が必要です。
# dfを参照, dfを変更するとdf_copyの値も変更される df_copy = df #dfをコピー, dfを変更しても, df_copyには反映されない df_copy = df.copy()
7(データ型の確認)
DataFrame の各列のデータ型は dtypes で確認できます。また、series のデータ型は dtype で確認できます。
df = initialize1() #初期化 print(df.dtypes) print("--------------") #出力したときにわかりやすいように勝手についかしました print(df["cabin"].dtype)
8(データ型の変換と確認)
列のデータ型は astype で変更することができます。初めのデータ型を dtype で確認し、str 型(文字列型)に変換して、再度 dtype で確認します。
df = initialize1() #初期化 print(df["pclass"].dtype) df["pclass"] = df["pclass"].astype(str) print(df["pclass"].dtype)
str 型は object と出力されます。
9(レコード数(行数)の確認)
len() 関数を使って、DataFrame の行数を確認します。引数は DataFrame です。
df = initialize1() #初期化 len(df)
10(レコード数(行数)、各列のデータ型、欠損値の有無の確認)
DataFrame の情報を確認するには、info() 関数を用います。RangeIndex が行数、Data columns が列数、Non-Null Count がレコードが入っている数。
df = initialize1() #初期化
df.info()
11(要素の確認)
列の要素は unique() 関数で確認できます。
df = initialize1() #初期化 print(df["sex"].unique()) print(df["cabin"].unique())

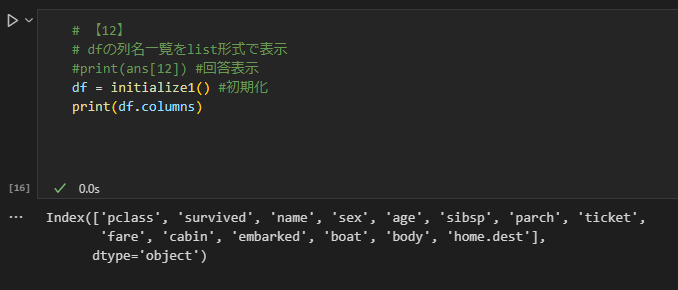
12(列名一覧を list 形式で表示)
列名一覧を表示するには、columns を使用します。columns ではデータフレームの列ラベルが取得できます。
print(df.columns)
これを list 形式に変換するには、tolist() 関数を使います。
print(df.columns.tolist())

list 形式ではなく、ndarray 形式にしたい場合は、values を使用します。

DataFrame と ndarray と list の基本的な違いは、利用するライブラリです。DataFrame は Pandas、ndarray は Numpy、list は Python 標準のものになります。
細かい違いもあります。ラベルを使えるものは DataFrame だけであったり、計算に特化したものが Numpy だったりします。下記リンク先で使い分けについて、説明されています。
13(インデックス一覧を ndarray 形式で表示)
index でインデックスの初期値、末項、項ごとの間隔を取得します。values を使い、ndarray 形式にして表示します。
df = initialize1() #初期化# print(df.index) #回答 print(df.index.values)
